
# IDE 概览
当平台搭建完毕后,后续的数据开发工作都将在 IDE 中完成。
IDE 是数据开发人员进行日常开发工作的工作台,提供图形化、拖拽式的数据开发体验。
支持对数据同步作业、数据加工作业(转换、作业)、通用模板作业、Shell程序、SQL程序、Spark程序、Flink程序、DI程序、MapReduce程序、Python程序、Procedure程序、作业流等作业的在线可视化开发。
# 操作说明
点击项目列表右侧的【项目开发】按钮,进入 DWS IDE 界面。
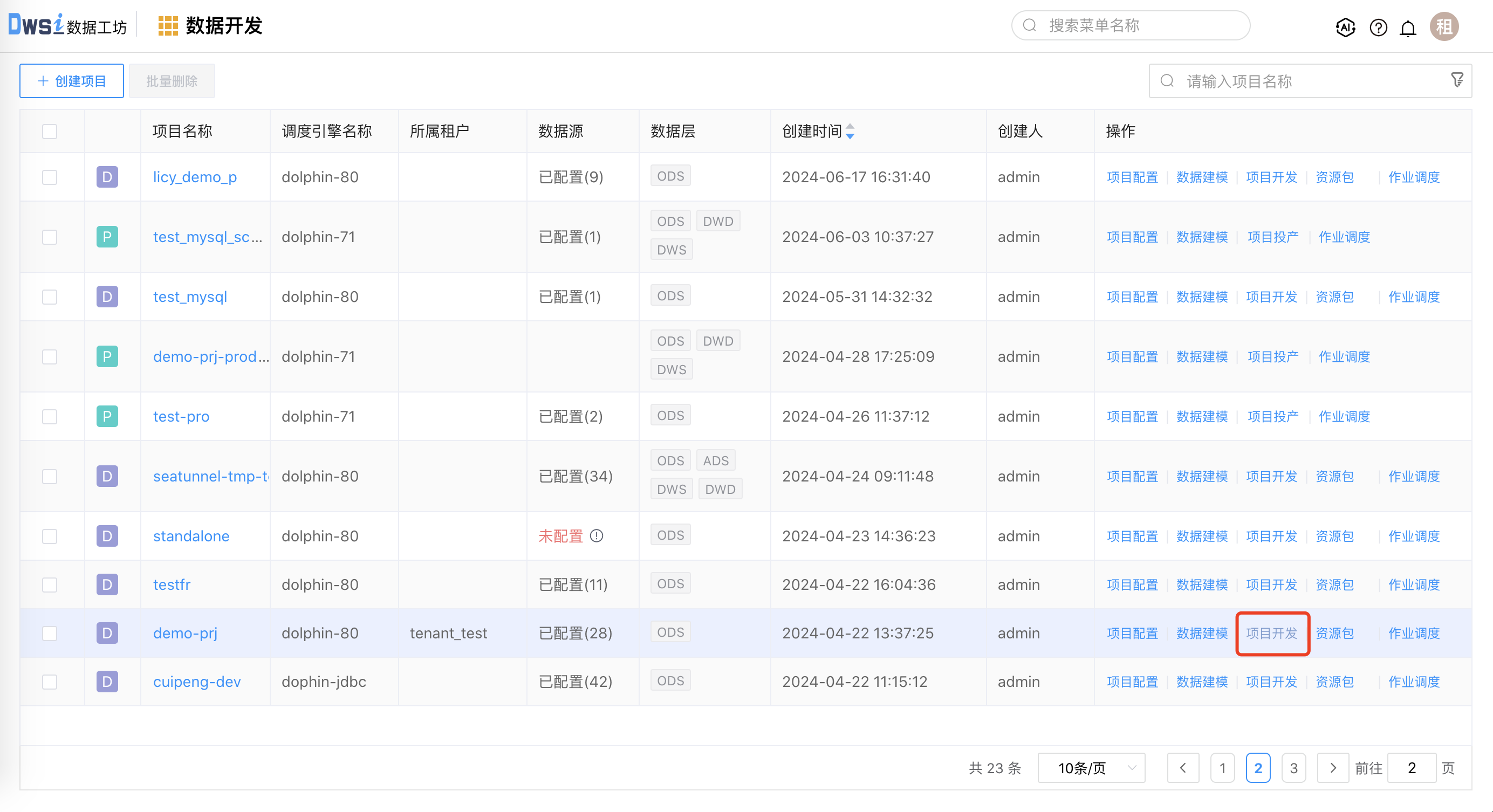
DWS IDE 界面如下图所示,分为三个区域:
资源树:项目的开发资源(数据同步、数据加工、通用模板、程序、作业流、数据源)以树形方式展示。
画布区:可视化开发集成作业/作业流,一个画布就是一个开发资源,可以通时展示多个画布。
- 通用配置:每个资源可以单独配置通用属性,包括:作业优先级、Worker 分组、作业组、作业组优先级、环境、命名参数、本地参数、超时告警、备注等。数据同步与数据加工的通用配置项有区别,参见后续详细说明。
- 指标日志:开启日志,记录作业运行后读、写、更新、输入、输出的数据量。数据加工作业及基于 Primeton DI 的通用模板作业需要在 IDE 中开启配置。可以在作业实例中查看作业类型为“PDI-TRANS、PDI-JOB、SEATUNNEL”的数据处理量。其他作业类型不支持查看数据量。
- 版本:显示版本记录。
- 草稿:显示草稿记录,最多保留最近 10 个草稿。
- 数据血缘:查看整个ETL流程的数据走向包括:数据源、表、字段血缘关系,默认不显示。需要在安装部署产品时手工配置开启,具体操作参见:数据血缘
- 运行:在线运行作业。
- 停止:停止作业的运行。
- 保存:保存修改后的草稿。
- 提交:修改后的资源提交后生成新的版本号。
日志栏:在线调试运行时,可以同步输出执行日志,便于用户查看执行过程。
- 刷新日志:刷新输出日志,以保持最新日志的输出。
- 刷新实例:刷新实例的执行状态,有三种状态:执行完毕、执行中、执行错误。
- 清空:清空当前输出的日志。
- 下载:当日志太多无法展示全,可以下载日志到本地。遇到异常无法自行解决时,可将此文件发给普元售后进一步分析。
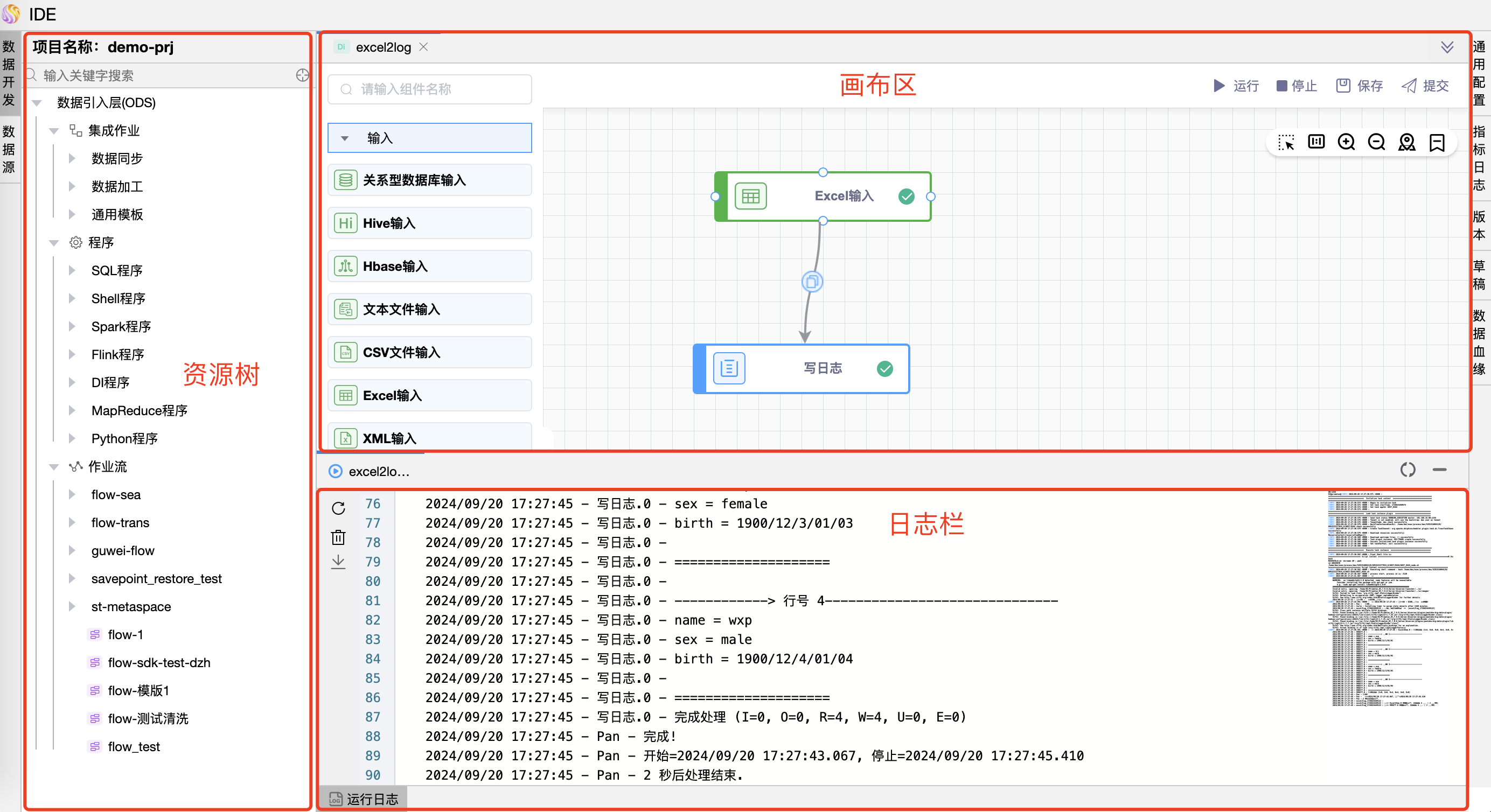
# 通用配置-数据同步
数据同步和基于 Seatunnel 的通用模板的通用配置项是一样的,有五类配置,包括基础信息、失败重试、超时机制、部署配置、引擎参数。如下图所示:
| 配置项 | 默认值 | 说明 |
|---|---|---|
| 作业名称 | 作业名称 | 当前已经创建/打开的数据加工作业名称。 |
| 作业优先级 | MEDIUM | 执行作业的优先级,共有五级: - HIGHEST:最高 - HIGH:高 - MEDIUM:中 - LOW:低 - LOWEST:最低 当 master 线程数不足时,级别高的流程在执行队列中会优先执行,相同优先级的流程按照先进先出的顺序执行。 |
| Worker分组 | default | 该作业在指定的 worker 机器组里执行。默认是 Default,可以在任一 worker 上执行。 |
| 作业组 | 无 | 如果项目已经添加了作业组配置,则可以在下拉框中进行选择。 |
| 作业组优先级 | 0 | 数字越大表明作业执行的优先级越高。 |
| 环境名称 | 无 | 如果项目已经添加了作业组配置,则可以在下拉框中进行选择,在作业执行时,根据 worker 分组选择对应的环境,最终由该组中的 worker 节点执行环境后执行该作业。 |
| 本地参数 | 无 | 调度的作业类型中自定义的参数,IN 是输入参数,OUT 是输出参数,需要使用${setValue(key=value)}的方式赋值。 |
| 失败重试次数 | 0 次 | 作业执行失败的重试次数 |
| 失败重试间隔 | 1 分钟 | 重试执行时的建个时间,单位为:分钟。 |
| 超时告警 | 不开启 | 设置是否启用超时告警的功能,开启后需要配置告警策略、超时时间。 |
| 告警策略 | 超时告警 | 两个选项: - 超时告警:当作业超过”超时时间”后,会发送告警邮件; - 超时失败:当作业超过”超时时间”后,作业执行失败。 |
| 超时时间 | 30分钟 | 设置作业执行的超时时间。 |
| 部署方式 | cluster | 两种选项: - cluster:适用于生产运行; - local:适用于开发及测试。 |
| 引擎参数 | 无 | 用于添加 Seatunnel 执行引擎的参数。可以配置key-value或者直接编写json。 |
| 并行度 | 1 | 最多并行执行的实例数。 |
| 备注 | 无 | 该作业的描述。 |
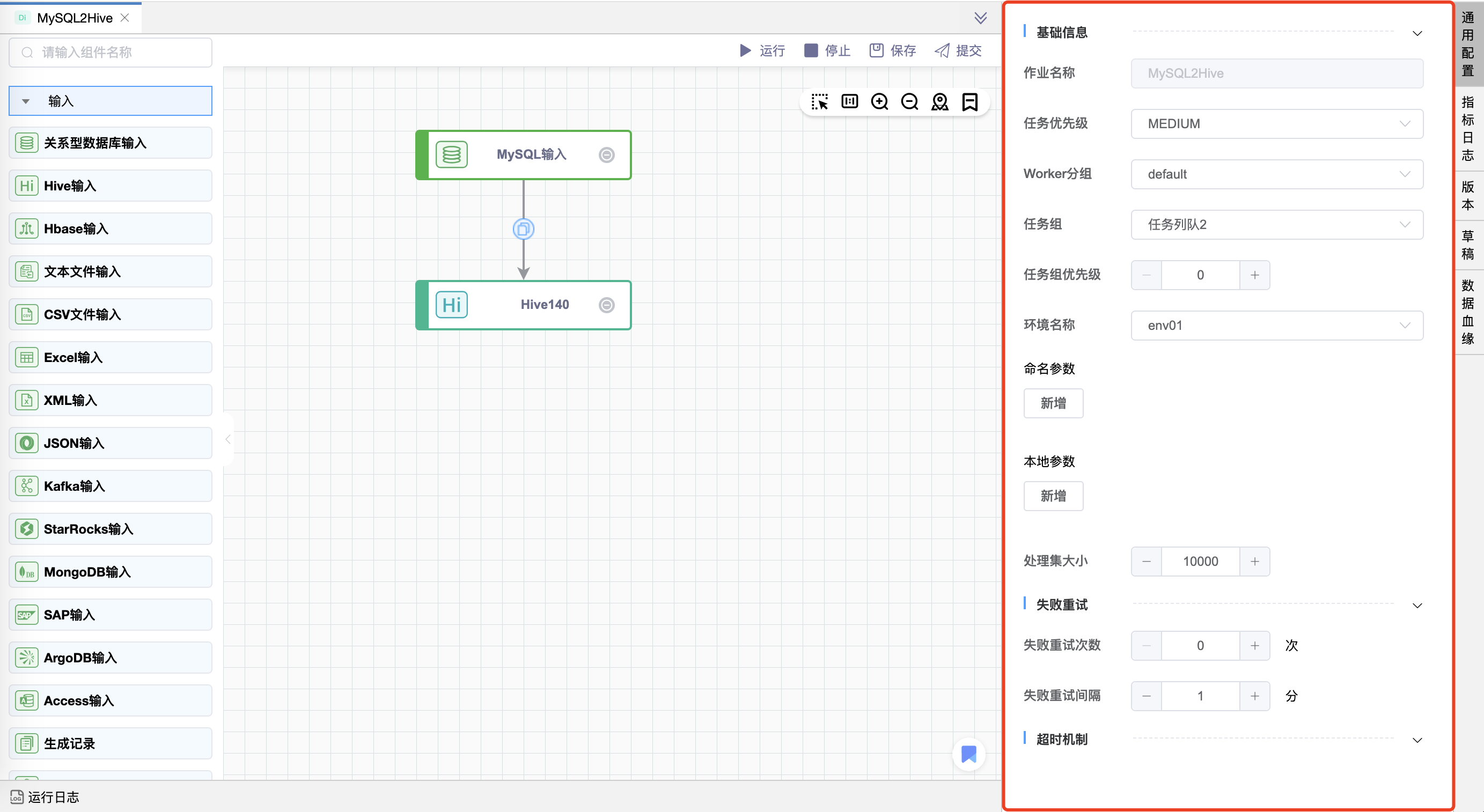
# 通用配置-数据加工
数据加工和基于 Primeton DI 的通用模板的通用配置项是一样的,有三类配置,包括基础信息、失败重试、超时机制。如下图所示:
| 配置项 | 默认值 | 说明 |
|---|---|---|
| 作业名称 | 作业名称 | 当前已经创建/打开的数据加工作业名称。 |
| 作业优先级 | MEDIUM | 执行作业的优先级,共有五级: - HIGHEST:最高 - HIGH:高 - MEDIUM:中 - LOW:低 - LOWEST:最低 当 master 线程数不足时,级别高的流程在执行队列中会优先执行,相同优先级的流程按照先进先出的顺序执行。 |
| Worker分组 | default | 该作业在指定的 worker 机器组里执行。默认是 Default,可以在任一 worker 上执行。 |
| 作业组 | 无 | 如果项目已经添加了作业组配置,则可以在下拉框中进行选择。 |
| 作业组优先级 | 0 | 数字越大表明作业执行的优先级越高。 |
| 环境名称 | 无 | 如果项目已经添加了作业组配置,则可以在下拉框中进行选择,在作业执行时,根据 worker 分组选择对应的环境,最终由该组中的 worker 节点执行环境后执行该作业。 |
| 命名参数 | 无 | 声明 key 和 default value。实际使用过程需要通过全局参数进行传参。 |
| 本地参数 | 无 | 调度的作业类型中自定义的参数,IN 是输入参数,OUT 是输出参数,需要使用${setValue(key=value)}的方式赋值。 |
| 处理集大小 | 10000 | 在进行ETL处理时,每次处理的数据量大小。增加数量可以减少事务次数,提高处理效率,但需要确保系统有足够的内存和处理能力。 |
| 失败重试次数 | 0 次 | 作业执行失败的重试次数 |
| 失败重试间隔 | 1 分钟 | 重试执行时的建个时间,单位为:分钟。 |
| 超时告警 | 不开启 | 设置是否启用超时告警的功能,开启后需要配置告警策略、超时时间。 |
| 告警策略 | 超时告警 | 两个选项: - 超时告警:当作业超过”超时时间”后,会发送告警邮件; - 超时失败:当作业超过”超时时间”后,作业执行失败。 |
| 超时时间 | 30分钟 | 设置作业执行的超时时间。 |
| 备注 | 无 | 该作业的描述。 |
# 通用配置-作业流
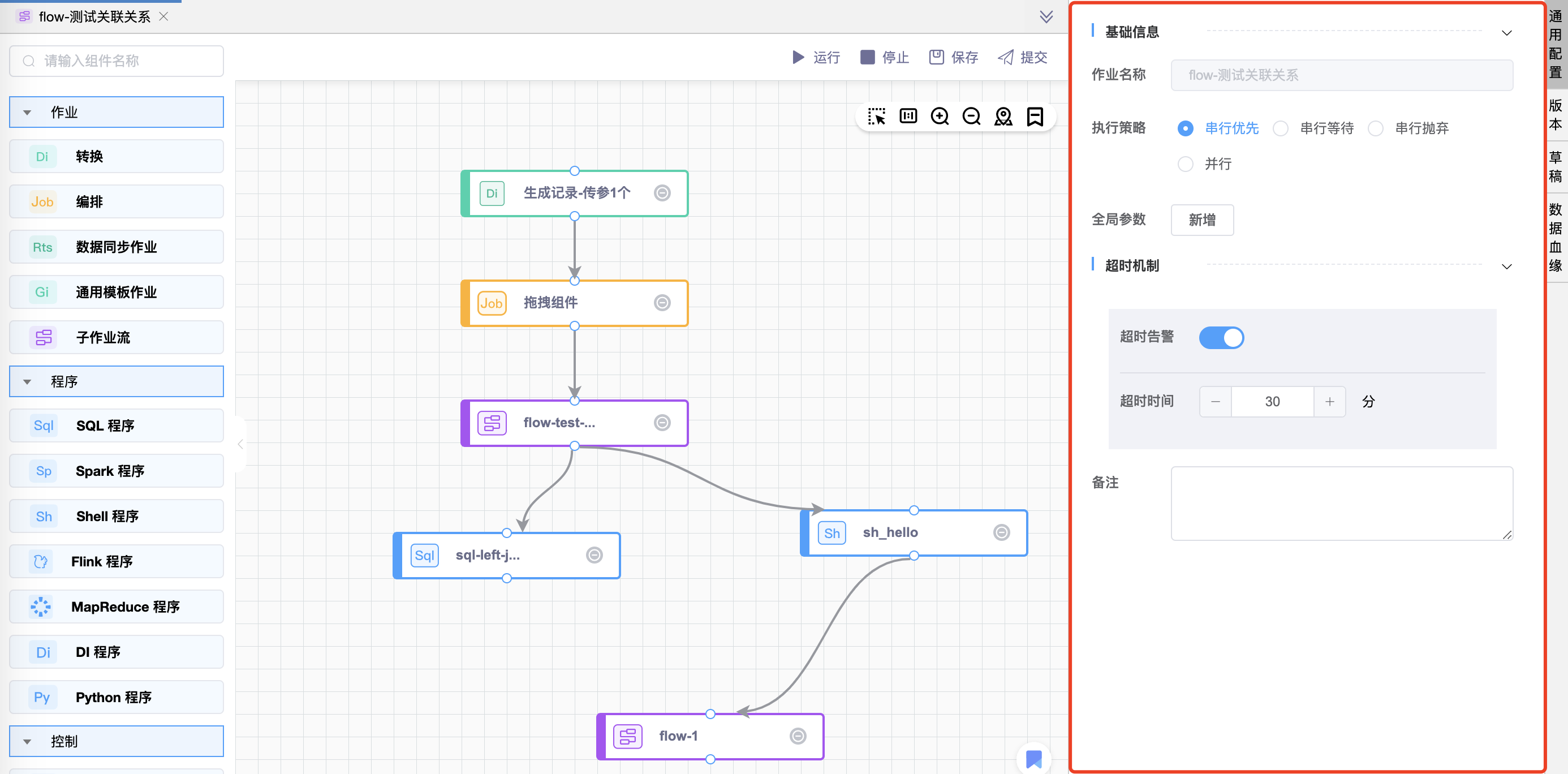
| 配置项 | 默认值 | 说明 |
|---|---|---|
| 作业名称 | 作业名称 | 当前已经创建/打开的数据加工作业名称。 |
| 执行策略 | 串行优先 | 当对于同一个作业流定义,同时有多个作业流实例时,共有四种执行策略: - 串行优先:停止先生成的作业流实例,执行后生成的作业流实例; - 串行等待:串行执行作业流实例,后生成的作业流实例状态为串行等待; - 串行抛弃:抛弃后生成的作业流实例,后生成的作业流实例状态为停止; - 并行:并行执行作业流实例。 |
| 全局参数 | 无 | 作业流中定义的参数。整个作业流的所有作业节点都可使用全局参数 |
| 超时告警 | 不开启 | 设置是否启用超时告警的功能,开启后需要配置超时时间。 |
| 超时时间 | 30分钟 | 设置作业执行的超时时间。 |
| 备注 | 无 | 该作业流的描述。 |
# 通用配置-参数说明
DWS 共有以下参数:命名参数、本地参数、全局参数、启动参数、上游作业传递的参数、内置参数、项目参数。使用参数格式为:${变量名}。
# 参数优先级
当参数名相同时参数的优先级从高到低为:启动参数 > 本地参数 > 上游作业传递的参数 > 全局参数 > 项目参数>命名参数。
# 名词解释
| 参数名称 | 配置入口 | 参数解释 | 作用域 |
|---|---|---|---|
| 命名参数 | 数据加工/PDI通用模板->通用配置->命名参数 | 只存在于【数据加工】类型及【通用模板】模型中处理引擎为Primeton DI的模型中。只作为输入参数 | 当前作业 |
| 本地参数 | 所有作业->通用配置->本地参数 | 所有作业中自定义的参数(包含数据加工、数据同步、通用模板、程序)。IN 是输入参数,OUT 是输出参数 | 当前作业 |
| 全局参数 | 作业流->通用配置->全局参数 | 作业流中定义的参数,IN 是输入参数,OUT 是输出参数。 | 当前作业流及其作业节点 |
| 启动参数 | 作业/作业流->试运行 | 作业或作业流试运行页面定义的变量。作业流试运行默认是将作业流的全局参数直接带出来,可修改。作业试运行默认是将本地参数直接带出来,可修改。 | 当前作业或当前作业流 |
| 上游作业传递的参数 | 作业/作业流->通用配置->本地/全局参数(OUT方向) | 作业流中上游作业节点通过本地参数设置OUT输出传递过来的参数,传递方向仅支持上游单向传递给下游。目前支持这个特性的作业类型有:Shell、SQL、Python、Procedure、子作业流。 | 作业流中当前作业的下游作业 |
| 内置参数 | 作业/作业流->通用配置->本地/全局参数 | 系统内置的参数,可以在所有作业流及作业节点中直接使用的参数 | 当前作业/作业流 |
| 项目参数 | 数据开发->项目配置->项目参数管理 | 项目参数管理中定义的参数,可以在该项目下的所有作业流及作业节点中直接使用的参数 | 当前项目下的所有作业流及作业 |
# 内置参数
内置参数分为基础内置参数和衍生内置参数。
# 基础内置参数:
| 变量名 | 声明方式 | 含义 |
|---|---|---|
| system.biz.date | ${system.biz.date} | 调度的前一天,格式为 yyyyMMdd |
| system.biz.curdate | ${system.biz.curdate} | 调度当天日期,格式为 yyyyMMdd |
| system.datetime | ${system.datetime} | 调度当天日期,格式为 yyyyMMddHHmmss |
| system.task.instance.id | ${system.task.instance.id} | 当前作业实例的ID |
| system.task.definition.name | ${system.task.definition.name} | 当前作业所属作业定义的名称 |
| system.task.definition.code | ${system.task.definition.code} | 当前作业所属作业定义的code |
| system.workflow.instance.id | ${system.workflow.instance.id} | 当前作业所属作业流实例ID |
| system.workflow.definition.name | ${system.workflow.definition.name} | 当前作业所属作业流定义的名称 |
| system.workflow.definition.code | ${system.workflow.definition.code} | 当前作业所属作业流定义的code |
| system.project.name | ${system.project.name} | 当前作业所在项目的名称 |
| system.project.code | ${system.project.code} | 当前作业所在项目的code |
# 衍生内置参数:
支持代码中自定义变量名,声明方式:${变量名}。可以是引用 "系统参数"。
这种基准变量为 $[...] 格式的,$[yyyyMMddHHmmss] 是可以任意分解组合的,比如:$[yyyyMMdd], $[yyyyMM],$[HHmmss], $[yyyy-MM-dd],$[yyyyMMdd-1]等。
也可以通过以下方式:
使用add_months()函数,该函数用于加减月份, 第一个入口参数为[yyyyMMdd],表示返回时间的格式 第二个入口参数为月份偏移量,表示加减多少个月
- 后 N 年:$[add_months(yyyyMMdd,12*N)]
- 前 N 年:$[add_months(yyyyMMdd,-12*N)]
- 后 N 月:$[add_months(yyyyMMdd,N)]
- 前 N 月:$[add_months(yyyyMMdd,-N)]
直接加减数字 在自定义格式后直接“+/-”数字
- 后 N 周:$[yyyyMMdd+7*N]
- 前 N 周:$[yyyyMMdd-7*N]
- 后 N 天:$[yyyyMMdd+N]
- 前 N 天:$[yyyyMMdd-N]
- 后 N 小时:$[HHmmss+N/24]
- 前 N 小时:$[HHmmss-N/24]
- 后 N 分钟:$[HHmmss+N/24/60]
- 前 N 分钟:$[HHmmss-N/24/60]
业务属性方式在自定义格式后直接“+/-”数字 支持日志格式:所有日期表达式,例如:yyyy-MM-dd/yyyyMMddHHmmss
当天:$[this_day(yyyy-MM-dd)],如:2022-08-26 => 2022-08-26
昨天:$[last_day(yyyy-MM-dd)],如:2022-08-26 => 2022-08-25
前(-)/后(+) N 月第一天:$[month_first_day(yyyy-MM-dd,-N)],如:N=1时 2022-08-26 => 2022-07-01
前(-)/后(+) N 月最后一天:$[month_last_day(yyyy-MM-dd,-N)],如:N=1时 2022-08-28 => 2022-07-31
前(-)/后(+) N 周的周一:$[week_first_day(yyyy-MM-dd,-N)],如:N=1 2022-08-26 => 2022-08-15
前(-)/后(+) N 周的周日:$[week_last_day(yyyy-MM-dd,-N)],如:N=1 2022-08-26 => 2022-08-21