# 关系型数据库数据写入Neo4j
本示例主要演示从mysql中读取数据,输出到Neo4j图库中。
主要步骤如下:
# 准备数据
在 MySQL数据源中创建一个表 orderinfo,并初始化一些数据。
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for orderinfo
-- ----------------------------
DROP TABLE IF EXISTS `orderinfo`;
CREATE TABLE `orderinfo` (
`ordercode` varchar(32) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL COMMENT '订单号',
`amount` int NULL DEFAULT NULL COMMENT '数量',
`price` varchar(32) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL COMMENT '价格',
`manufacturer` varchar(32) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL COMMENT '厂商',
`createtime` date NULL DEFAULT NULL COMMENT '创建时间',
`createuser` varchar(32) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL COMMENT '创建人',
`updatetime` timestamp NULL DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`ordercode`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of orderinfo
-- ----------------------------
INSERT INTO `orderinfo` VALUES ('001', 1000, '5000', 'xingyun', '2018-12-13', 'zhangcong', '2020-01-01 00:00:00');
INSERT INTO `orderinfo` VALUES ('002', 500, '1000', '西安金属', '2018-12-13', '王强', '2018-12-15 23:59:59');
INSERT INTO `orderinfo` VALUES ('004', 20000, '75000', '星峰', '2018-12-13', '王林', '2018-12-13 12:00:00');
INSERT INTO `orderinfo` VALUES ('005', 1300, '8000', '天威科技', '2018-12-13', '王林', '2019-12-01 00:00:00');
SET FOREIGN_KEY_CHECKS = 1;
# 新建同步作业
点击数据同步上的【...】,选择弹出菜单【新建数据同步作业】,作业名称为:mysql-neo4j。
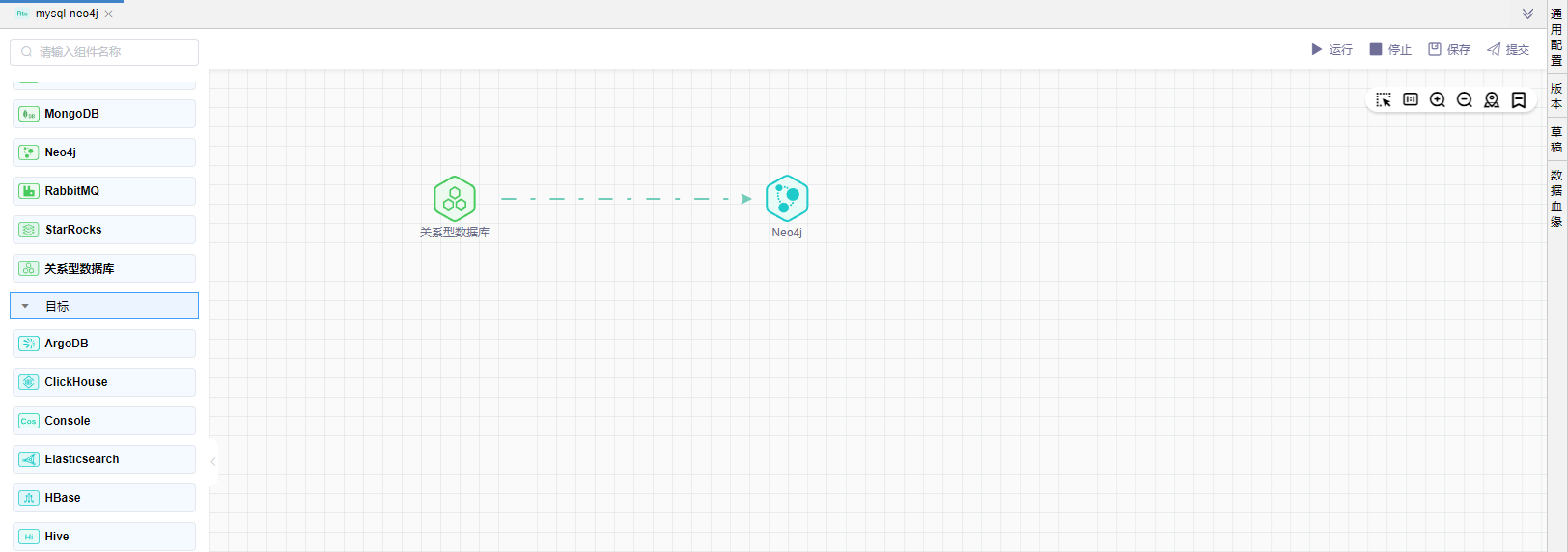
# 拖拽图元
依次拖拽数据源中的关系型数据库组件、目标中的Neo4j Sink组件,依次连线。如下图所示:
# 配置组件属性
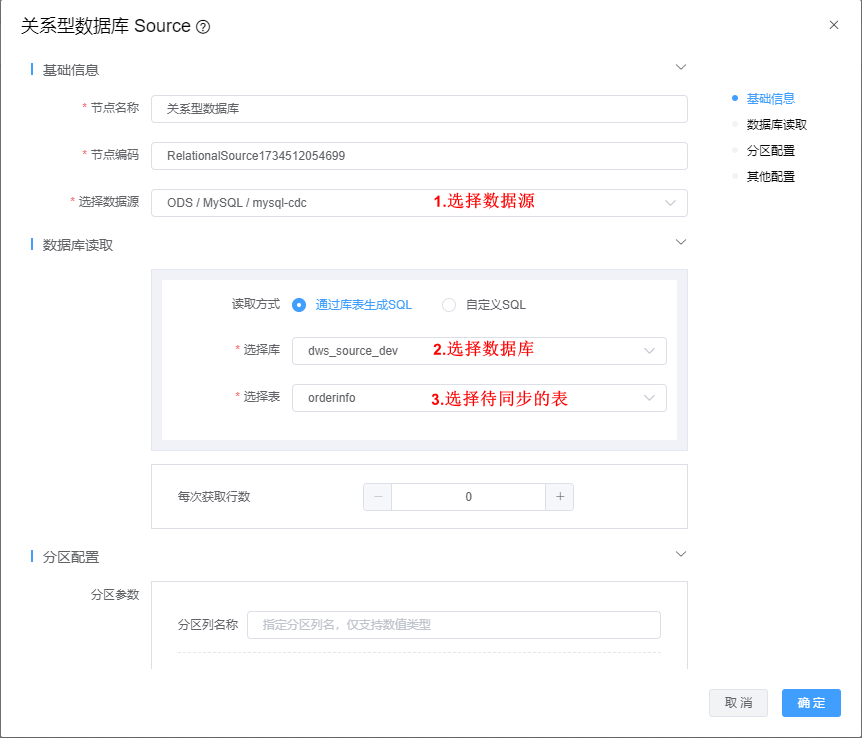
1、双击"关系型数据库"组件,根据下图所示步骤依次配置。
2、双击"Neo4j Sink"组件,根据下图所示步骤依次配置。
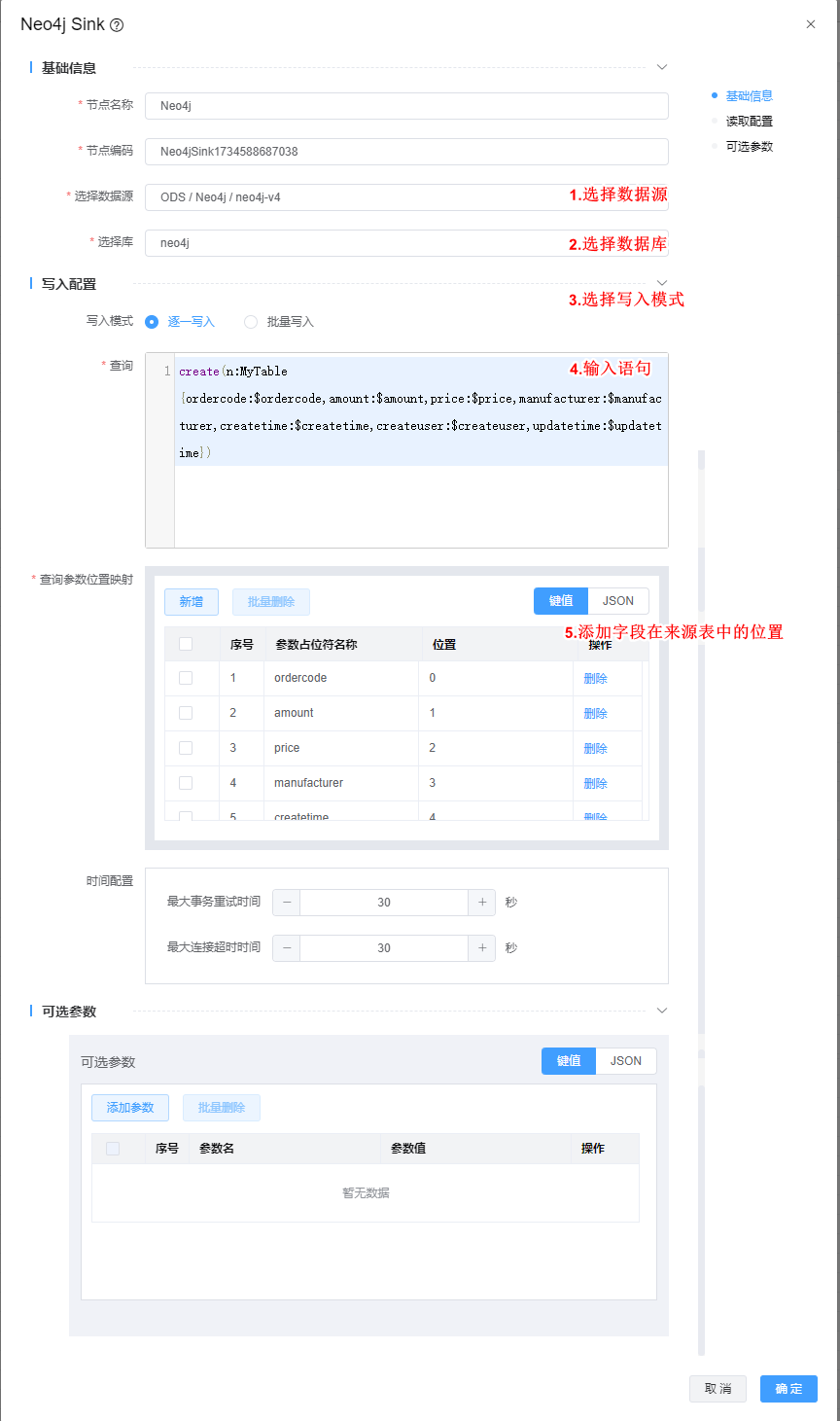
- 写入模式分为逐一写入和批量写入
- 选择逐一写入:查询字段值为:create(n:MyTable {ordercode:$ordercode,amount:$amount,price:$price,manufacturer:$manufacturer,createtime:$createtime,createuser:$createuser,updatetime:$updatetime})
- 选择批量写入:查询字段值为:unwind $batch as row create(n:MyTable) set n.ordercode = row.ordercode,n.amount = row.amount,n.price = row.price,n.manufacturer = row.manufacturer,n.createtime = row.createtime,n.createuser=row.createuser,n.updatetime = row.updatetime
- 查询参数位置映射:指要写入的字段在原表中字段的位置,位置从0开始。
3、Ctrl+S保存该模型。
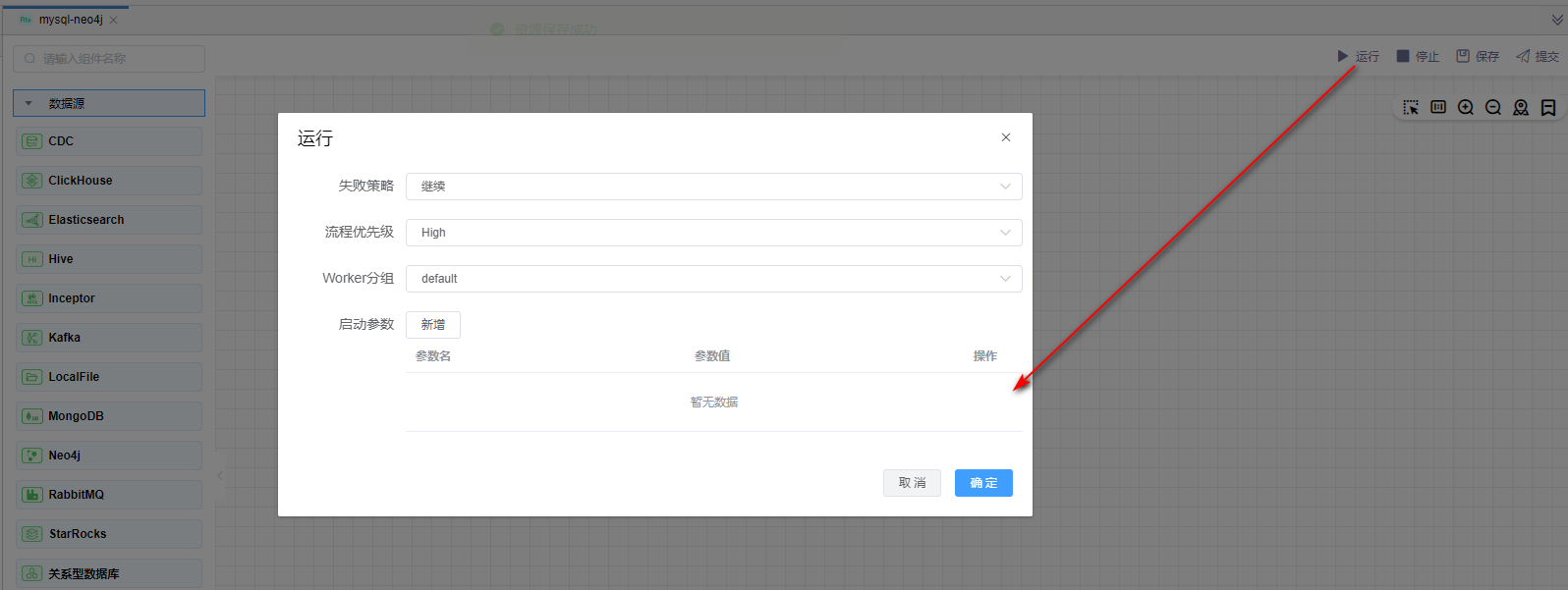
# 运行
点击【运行】按钮,可以运行已经开发完毕的场景,在日志栏可以看运行日志及运行结果。
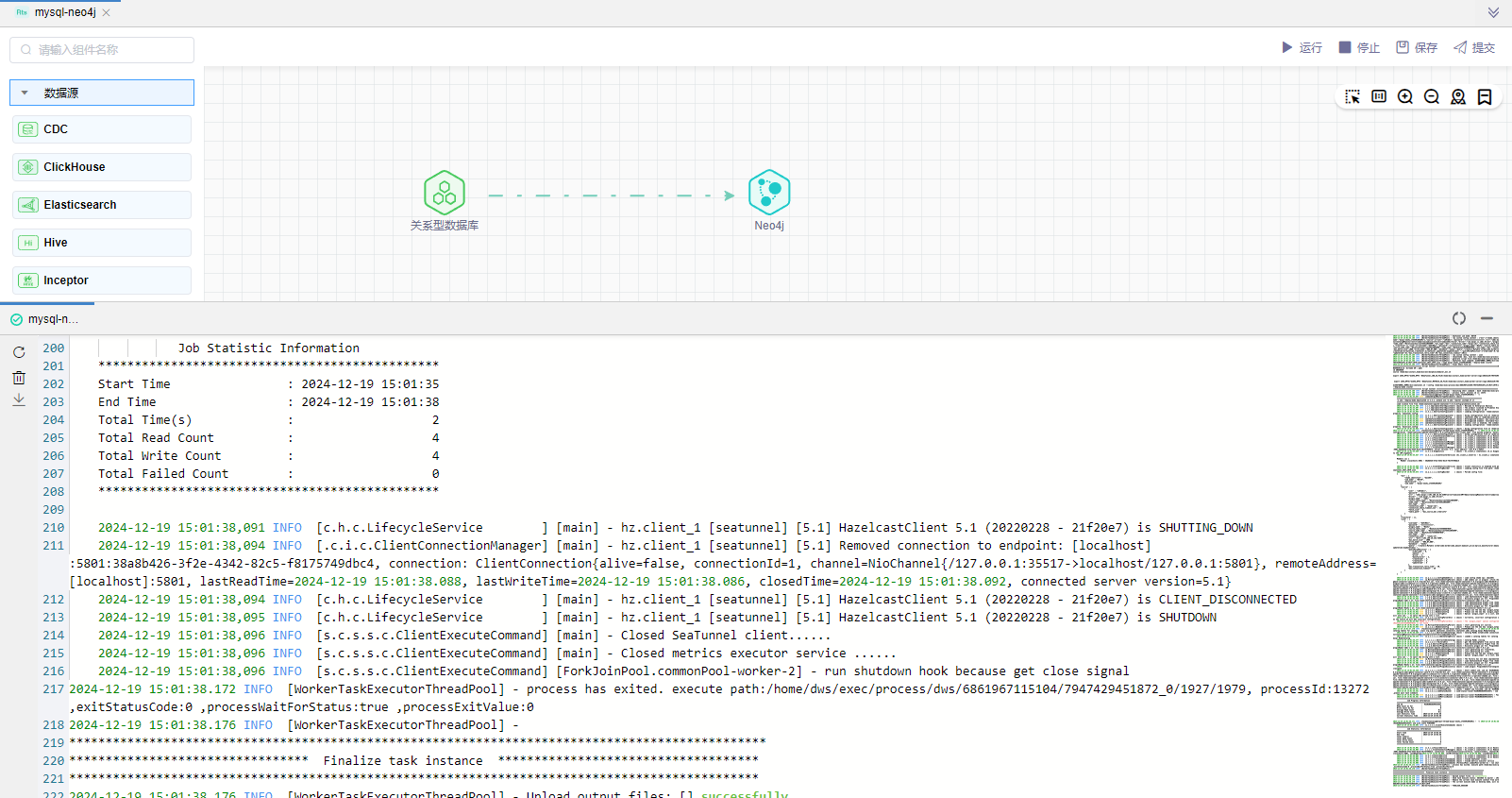
# 查看数据
运行日志显示作业运行成功,输出4条数据。
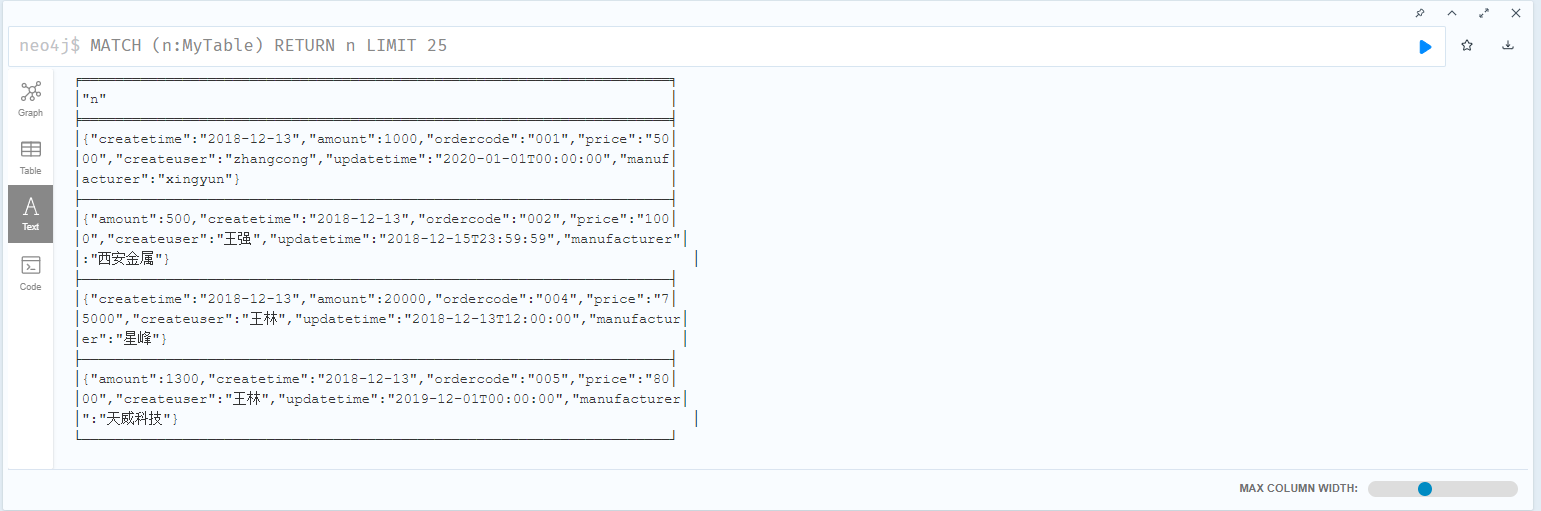
Neo4j客户端中查看有4条数据
# 提交版本
当草稿运行正常后,点击【提交】按钮可以将该版本提交到作业调度,每次修改提交都会生成新的版本,可以看到提交的历史版本,并可以随意切换版本。
提交后的版本,可以在作业调度中进行"定时"调度配置。